
What you should know to master data preprocessing !
Welcome to the Data Preprocessing Mastery Workshop! Greetings Data Enthusiasts,
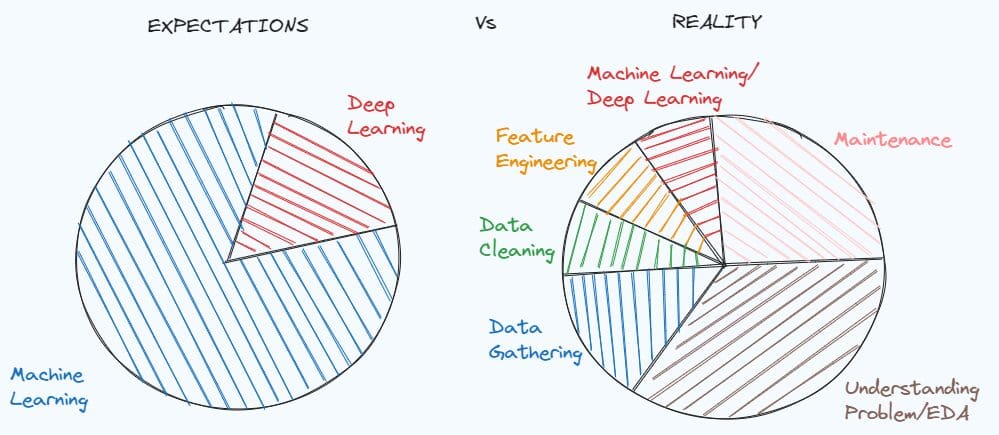
In the vast landscape of data science, the journey from raw data to meaningful insights begins with a crucial step: Data Preprocessing. Today, we embark on a journey to unravel the intricacies of this fundamental process that lays the foundation for robust analyses and powerful machine learning models.
What to Expect:
Over the next 2 hours, we will delve into the intricacies of preprocessing numerical, categorical, text, and temporal data. Each section will be a blend of theoretical concepts and hands-on exercises, ensuring that you not only understand the ‘why’ but also gain practical experience with the ‘how.’
Our goal is to empower you with the knowledge and tools to transform raw data into a valuable asset, enabling you to make informed decisions and build robust machine learning models.
Let’s Dive In:
So, without further ado, let’s dive into the world of Data Preprocessing. Whether you’re a seasoned data professional looking to refine your skills or a newcomer eager to unlock the mysteries of data, this workshop is tailored to meet you where you are.
Get ready to unravel the complexities, overcome challenges, and master the art of Data Preprocessing!
Let’s begin the journey!
What is Data preprocessing exactly ??
Data preprocessing is the process of transforming raw data into an understandable format. It is also an important step in data mining as we cannot work with raw data. The quality of the data should be checked before applying machine learning or data mining algorithms.
Major Tasks in Data Preprocessing :
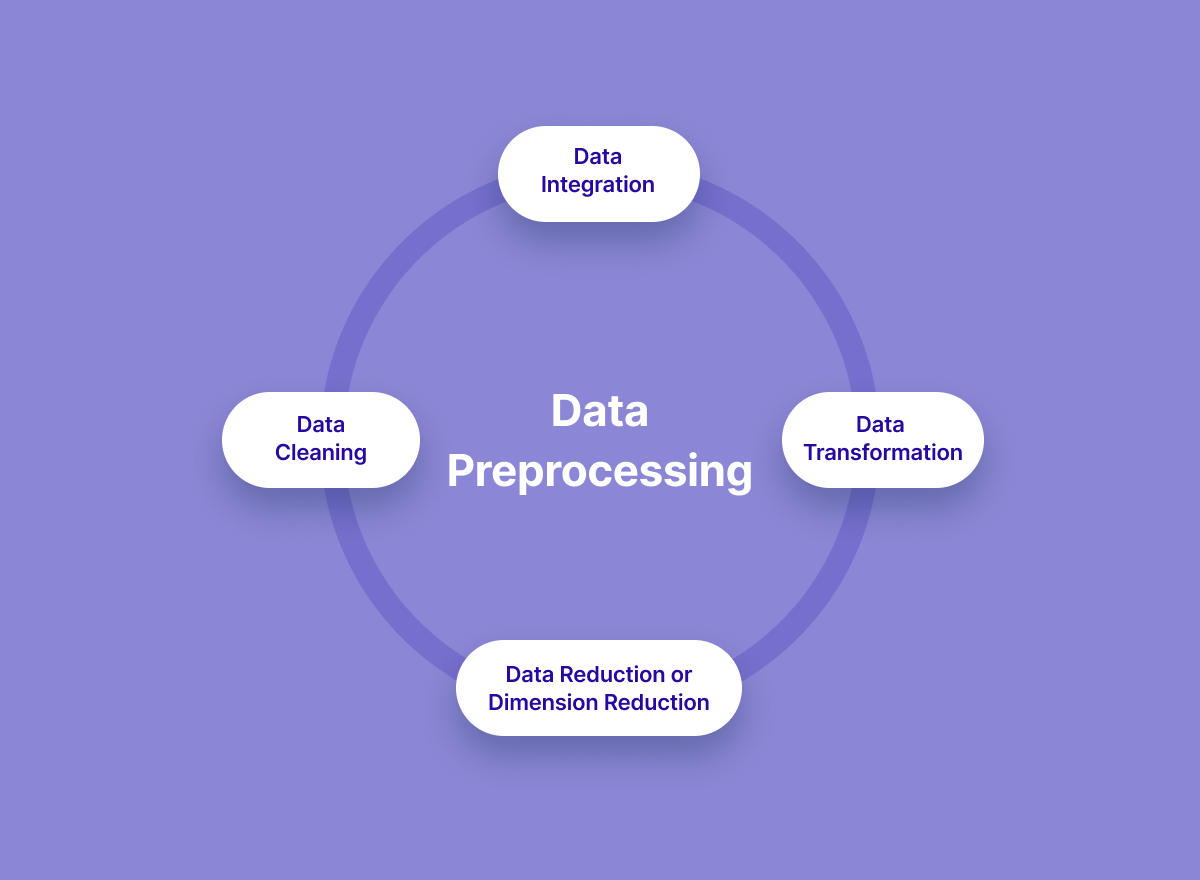
1. Data Cleaning:
- Handling Missing Values:
- Imputation: Replace missing values with a calculated or estimated value (mean, median, mode).
- Removal: Exclude rows or columns with missing values.
- Advanced Imputation: Use machine learning algorithms for more accurate imputation.
- Outlier Management:
- Identification: Detect and flag outliers using statistical methods.
- Treatment: Transform or remove outliers based on the impact on analysis.
- Inconsistency Resolution:
- Standardization: Ensure uniformity in data by converting to a consistent format.
- Cleaning: Correct errors in data entry, spelling, or formatting.
2. Data Integration:
- Combining Datasets:
- Concatenation: Stack datasets vertically or horizontally.
- Merging: Combine datasets based on common keys or columns.
- Handling Redundancies:
- Deduplication: Remove duplicate records.
- Aggregation: Consolidate data by grouping and summarizing.
- Handling Inconsistencies:
- Standardization: Normalize data to a common scale.
- Transformation: Convert data to a consistent format.
3. Data Reduction:
- Dimensionality Reduction:
- Principal Component Analysis (PCA): Reduce dimensionality while retaining important features.
- Feature Selection: Choose the most relevant features based on importance scores.
- Sampling Techniques:
- Oversampling: Increase instances of the minority class.
- Undersampling: Decrease instances of the majority class.
- Binning and Discretization:
- Group numerical data into bins or categories.
- Simplify data for easier analysis.
4. Data Transformation:
- Handling Numerical Data:
- Scaling: Normalize or standardize numerical features.
- Log Transformation: Address skewness in data.
- Wrangling Categorical Data:
- Encoding: Convert categorical variables into numerical representations (one-hot encoding, label encoding).
- Rare Category Management: Handle infrequent categories to prevent sparsity.
- Text Data Transformation:
- Tokenization: Break down text into tokens.
- Text Cleaning: Remove stop words, punctuation, and apply stemming or lemmatization.
- Temporal Data Transformation:
- Feature Extraction: Extract relevant features from date and time data.
- Time Zone Standardization: Ensure uniformity in time zone representation.
What is the best way to preprocess data with different types?
1.Numerical Data :
Numerical data is data that can be measured or counted, such as age, height, weight, income, or temperature. This type of data can be further divided into continuous or discrete, depending on whether it has a finite or infinite range of values.
Preprocessing numerical data techniques
- scaling or normalizing the data to reduce the effect of outliers and different units of measurement. This can be done using min-max scaling, standardization, or robust scaling.
Scaling or Normalizing Numerical Data
When working with numerical data, it’s often essential to scale or normalize the data to mitigate the impact of outliers and accommodate different units of measurement. Common techniques for this purpose include:
Min-Max Scaling:
- Objective: Transform the data to a specific range (usually [0, 1]) to ensure all features have the same scale.
- Explanation: It linearly scales the data, mapping the minimum value to 0 and the maximum value to 1. Useful when features have different ranges and you want to bring them to a common scale.
```python
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
scaled_data = min_max_scaler.fit_transform(numerical_data)
```
Standardization:
- Objective: Standardize the data to have a mean of 0 and a standard deviation of 1.
- Explanation: It transforms the data to have a standard normal distribution. Useful when the features have different units and you want them to be comparable.
```python
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standardized_data = standard_scaler.fit_transform(numerical_data)
```
Robust Scaling:
- Objective: Scale the data while handling outliers robustly.
- Explanation: It uses the median and the interquartile range (IQR) to scale the data. It’s less sensitive to outliers compared to min-max scaling and standardization.
```python
from sklearn.preprocessing import RobustScaler
robust_scaler = RobustScaler()
robust_scaled_data = robust_scaler.fit_transform(numerical_data)
```
Considerations:
- Use Min-Max Scaling when you need data in a specific range.
- Use Standardization when you want features to have a mean of 0 and a standard deviation of 1.
-
Use Robust Scaling when dealing with datasets containing outliers, as it is less influenced by extreme values.
- Handling missing values can be handled by imputing them with a mean, median, mode, or a custom value.
- Dimensionality reduction techniques such as principal component analysis (PCA) or linear discriminant analysis (LDA) can be applied to select the most relevant features and improve the performance and interpretability of the models.
2.categorical data :
Encoding Categorical Data
Encoding categorical data is the process of converting categorical variables into a numerical format so that they can be used as inputs for machine learning models. Categorical variables are those that can take on a limited, and usually fixed, number of possible values or categories.
Common Encoding Methods
Label Encoding
- Assigns a unique integer to each category. Suitable for ordinal data where the order matters.
- Example:
['Red', 'Green', 'Blue']might be encoded as[0, 1, 2].from sklearn.preprocessing import LabelEncoder label_encoder = LabelEncoder() encoded_labels = label_encoder.fit_transform(['Red', 'Green', 'Blue'])One-Hot Encoding
Creates binary columns for each category and indicates the presence of the category with a 1 or 0.Suitable for nominal data where there is no inherent order among categories. Example: [‘Red’, ‘Green’, ‘Blue’] might be encoded as three columns: Red (1 or 0), Green (1 or 0), Blue (1 or 0).
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
# Create a DataFrame with categorical data
data = pd.DataFrame({'Color': ['Red', 'Green', 'Blue']})
# Apply one-hot encoding
one_hot_encoder = OneHotEncoder()
encoded_data = one_hot_encoder.fit_transform(data[['Color']]).toarray()
3.Textual Data
Textual data, such as reviews, tweets, emails, or articles, is data that consists of words, sentences, or documents and is typically unstructured and complex. Consequently, it requires more preprocessing steps than other data types. Common preprocessing steps:
- cleaning the data by removing punctuation, stopwords, numbers, HTML tags, or other irrelevant characters to reduce the noise and improve the readability of the text.
import re from nltk.corpus import stopwords def clean_text(text): # Remove punctuation and numbers text = re.sub(r'[^\w\s]', '', text) # Remove stopwords stop_words = set(stopwords.words('english')) text = ' '.join(word for word in text.split() if word.lower() not in stop_words) return text - Tokenizing the data into smaller units such as words, characters, or n-grams can help capture the meaning and structure of the text.
from nltk.tokenize import word_tokenize
def tokenize_text(text):
# Tokenize the text into words
tokens = word_tokenize(text)
return tokens
- Vectorizing the data by converting it into numerical values that represent the frequency, importance, or similarity of the tokens can be done using methods such as count vectorizer, term frequency-inverse document frequency (TF-IDF), or word embeddings.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from gensim.models import Word2Vec
# Example text data
text_data = ["This is an example sentence.", "Another example for preprocessing."]
# Count Vectorizer
count_vectorizer = CountVectorizer()
count_matrix = count_vectorizer.fit_transform(text_data)
# TF-IDF Vectorizer
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(text_data)
# Word Embeddings (Word2Vec)
word2vec_model = Word2Vec(sentences=[word_tokenize(sentence) for sentence in text_data], vector_size=100, window=5, min_count=1, workers=4)
word_embeddings = [word2vec_model.wv[word] for sentence in text_data for word in word_tokenize(sentence)]