Analyse des données Velib "Etude de cas"
Ce projet est a la base un test technique pour le poste stagiare data scientist.
Theme: Mobilité et Espace Public
Sujet: disponibilité des velos en temps reel
Angle d’etude: Comment on peut classer les quartiers selon l’activité du reseau Velib!!
Plan
- Recuperation des données de l’API velib
- Stockage des données
- Acquisition des données
- Comprendre notre jeu de donnée
- Classification automatique non supervisée
la 1 ere etape c’est de comprendre le jeu de donnée velib qui est du opendata-paris mais avant on a besoin de recuperer les donnée avec python en utilisant API .
1.Recuperation des données de l’API velib
Plus concrètement, regardons en détail ce que contiennent ces données avec Python. Pour ce faire, nous allons utiliser le module requests pour lancer une requête sur l’API de Vélib. Notre première requête porte sur les caractéristiques des stations Vélibs
import requests
answer = requests.get("https://velib-metropole-opendata.smoove.pro/opendata/Velib_Metropole/station_information.json").json()
print(answer.keys())
On obtient en retour un fichier JSON, que l’on peut manipuler comme un dictionnaire Python, avec 3 clefs : lastUpdatedOther l’indication de la date de dernière mise à jour des données, ttl la durée de vie des données avant de devenir obsolète et enfin data les données proprement dîtes.
Pour manipuler ces données, nous allons utiliser le module Pandas. C’est un outil puissant d’analyse de données dont la base est l’objet DataFrame
import pandas as pd
df_1 = pd.DataFrame(answer["data"]["stations"])
df_1.head()
On voit que pour chaque station, nous disposons de son nom, de son identifiant unique station_id et de sa position en latitude lat et longitude lon. Ce sont des données à durée de vie longue que nous allons garder sous le bras. On ne s’attend pas à ce que des stations se déplacent ou bien changent de nom toutes les 5 minutes.
Une requête que nous allons effectuer très régulièrement concerne l’occupation des stations :
answer = requests.get("https://velib-metropole-opendata.smoove.pro/opendata/Velib_Metropole/station_status.json").json()
df_2 = pd.DataFrame(answer["data"]["stations"])
df_2.head()
Pour chaque station, nous obtenons en temps réel (les données sont mises à jour toutes les minutes) le nombre de vélibs mis à disposition, le nombre de places disponibles et même la décomposition entre le nombre de vélos mécaniques et électriques. Congrats 🎉:Mission accomplie nous avons recuperer les donnée en utilisant API et python.
2.Stockage des données
Maintenant que nous savons récupérer les données Vélib, nous allons pouvoir les stocker sous la forme d’une base de données persistante SQLITE3. Pour faire simple, il s’agit d’une base de données dite légère (mais puissante !) qui se présente sous la forme d’un simple fichier. C’est un format très pratique pour de petits projets comme le notre ou pour la phase de développement de plus gros projets. Avec Pandas, la procédure est limpide :
# On supprimse les données inutiles
del df_1["stationCode"]
del df_1["rental_methods"]
del df_2["numBikesAvailable"]
del df_2["num_bikes_available_types"]
del df_2["numDocksAvailable"]
del df_2["is_installed"]
del df_2["is_returning"]
del df_2["is_renting"]
del df_2["last_reported"]
# On crée un marqueur temporel
time_stamp = pd.Timestamp.now()
df_2["time_stamp"] = time_stamp
# On enregistre sous forme de base SQLITE
df_1.to_sql("localisation", "sqlite:///data.db", if_exists="replace")
df_2.to_sql("stations", "sqlite:///data.db", if_exists="append")
La commande se lit : j’envoie le DataFrame df_1 vers SQL sous le nom de table localisation et dans la base SQLITE data.db. Si la table existe alors on la remplace. Pour les données en temps réel, on ajoute un marqueur temporel qui permet de garder en mémoire l’heure d’acquisition des données. Notez l’option if_exists=”append” : à chaque nouvelle acquisition, on ajoute de nouvelles lignes à la table. Concrètement, le marqueur temporel ressemble à ça
time_stamp
output:Timestamp('2022-10-09 01:38:18.399282')
Le marqueur retient la date et l’heure précise à laquelle j’écris ces lignes. Et ce sera la même chose pour nos données d’occupation des stations Vélib.
3. Acquisition des données
Il ne nous reste plus qu’à automatiser l’acquisition de données toutes les minutes. Il existe un module python pour ça qui s’appelle APScheduler. Ce module permet l’automatisation et la planification de tâches, et nous utiliserons l’objet BlockingScheduler. Son utilisation est la suivante :
from apscheduler.schedulers.blocking import BlockingScheduler
sched = BlockingScheduler()
@sched.scheduled_job("interval", seconds=5)
def print_date():
time_stamp = pd.Timestamp.now()
print(time_stamp)
sched.start()
Avec le décorateur @sched.scheduled_job(“interval”, seconds=5), on indique que la fonction doit être appelée régulièrement avec un intervalle de temps de 5 secondes.
Nous avons maintenant tous les ingrédients pour lancer une acquisition de données.
4. Comprendre notre jeu de donnée
Nous allons maintenant pouvoir jouer avec nos belles données toutes fraiches. Commençons par importer les deux tables dans deux DataFrames distincts
data_stations = pd.read_sql_table("stations", "sqlite:///database.db")
data_localisation = pd.read_sql_table("localisation", "sqlite:///database.db")
data_stations.head()
Notre table stations contient environ 2 millions de lignes, un index et 5 colonnes : le code de la station stationCode, l’identifiant de la station station_id, le nombre de vélos disponibles num_bikes_available, le nombre de bornes libres num_docks_available ainsi que notre marqueur temporel time__stamp.
Manipulation des données : jointure
Pour en savoir plus sur une station, il faut faire la correspondance avec notre table localisation. Une première approche serait de faire une sélection sur cette autre table avec notre station_id, et cela fonctionne très bien !
data_localisation[data_localisation["station_id"] == 213688169]

Cette mystérieuse station se nomme donc Benjamin Godard - Victor Hugo avec une capacité de 35 vélos et nous avons même ses coordonnées géographiques ! On pourrait de la même manière mettre en relation chacune de nos observations avec des sélections, mais ce serait très inefficace. La bonne manière de procéder, bien connue quand on manipule des bases de données, c’est de faire une jointure.
Dit simplement, on va fusionner les deux tables et aligner les lignes qui partagent certaines propriétés. Ici, nous souhaitons mettre en commun les informations sur les stations qui partagent un même identifiant station_id. Il existe plusieurs types de jointures et nous ne nous attarderons pas davantage sur la dénomination exacte. Avec Pandas, la syntaxe est plutôt claire
data_stations = data_stations.merge(data_localisation, on="station_id")
data_stations
![]() À l’issue de cette fusion, nous disposons d’une table plus grande, avec le même nombre de lignes (et donc d’observations), mais disposant de cinq colonnes supplémentaires issues de la seconde table. Nous avons ici, toutes les données nécessaires pour commencer l’analyse spatiale de ces fameuses données Vélib.
À l’issue de cette fusion, nous disposons d’une table plus grande, avec le même nombre de lignes (et donc d’observations), mais disposant de cinq colonnes supplémentaires issues de la seconde table. Nous avons ici, toutes les données nécessaires pour commencer l’analyse spatiale de ces fameuses données Vélib.
Faisons quelques statistiques de base :
print("There are {0} Velib stands in Paris".format(velib_data.address.count()))
print("There are {0} bike stands in total".format(velib_data.bike_stands.sum()))
print("There are {0} available bikes".format(velib_data.available_bikes.sum()))
print("There are {0} available bikes stands".format(velib_data.available_bike_stands.sum()))
print("")
bike_stands_max = velib_data.bike_stands.max()
bike_stands_max_query = "bike_stands == " + str(bike_stands_max)
print("Biggest stations with {0} bike stands:".format(bike_stands_max))
print(velib_data.query(bike_stands_max_query).address.values)
print("")
bike_stands_min = velib_data.bike_stands.min()
bike_stands_min_query = "bike_stands == " + str(bike_stands_min)
print("Smallest stations with {0} bike stands:".format(bike_stands_min))
print(velib_data.query(bike_stands_min_query).address.values)
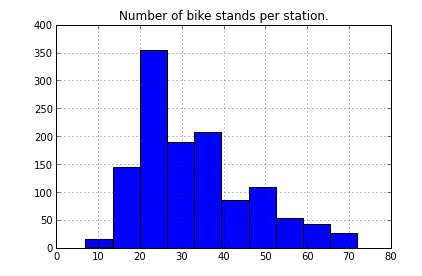
 Nombre de stands par station:
Nombre de stands par station:
stands.hist();
title("Number of bike stands per station.");
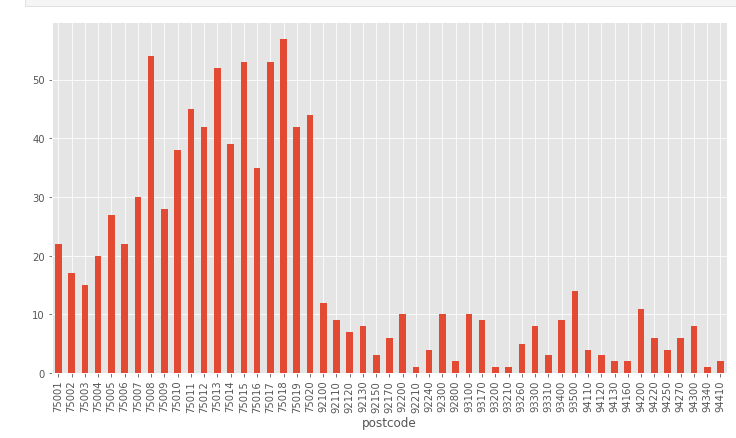
 Maintenant, on recupere un code postal des adresses en utilisant une expression régulière, et on le stocke dans une nouvelle colonne. On pressente ensuite un histogramme pour montrer le nombre de stations par zone:
Maintenant, on recupere un code postal des adresses en utilisant une expression régulière, et on le stocke dans une nouvelle colonne. On pressente ensuite un histogramme pour montrer le nombre de stations par zone:
import re
velib_data['postcode'] = velib_data['address'].apply(lambda x: re.findall('\d{5}',x)[0] )
plt.figure(figsize=(10, 6))
velib_data.groupby('postcode').size().plot.bar();
plt.tight_layout()
Analyse spatiale
nous allons analyser ces données spatiales en utilisant la librairie GeoPandas. Cette librairie présente beaucoup de similarité avec Pandas. L’objet de base s’appelle un GeoDataFrame, il s’agit d’un DataFrame avec une colonne spéciale nommée geometry qui contient des renseignements géographiques. Cette geometry peut être un point, comme dans le cas présent, mais aussi une ligne pour désigner une frontière ou bien un polygone pour matérialiser un territoire. Nous reviendrons sur ce dernier point dans quelques instants.
La première étape consiste à convertir notre couple (longitude, latitude) en un object Point reconnu par GeoPandas, puis à créer notre GeoDataFrame.
import geopandas as gpd
# Convert the longitude and latitude to a format recognized by geoPandas
geometry = gpd.points_from_xy(data_stations["lon"], data_stations["lat"])
# Create a DataFrame with a geometry containing the Points
geo_stations = gpd.GeoDataFrame(
data_stations, crs="EPSG:4326", geometry=geometry
)
geo_stations
L’acronyme crssignifie Coordinate Reference System, c’est une indication du système de projection utilisé. En regardant la documentation Vélib, on voit que le référentiel de projection utilisé est WGS84. C’est le système de projection le plus commun aujourd’hui et il est notamment utilisé par les systèmes de positionnement par satellite GPS. Ce système est référencé 4326 en deux dimensions (X,Y) et 4979 en trois dimensions (X,Y,Z) selon la liste des codes EPSG, et c’est ce que nous donnons comme indication à notre GeoDataFrame.
premières cartes
Avant de faire une carte, nous allons sélectionner des données à un temps fixé, et les enregistrer dans un nouveau GeoDataFrame
some_time = geo_stations["time_stamp"][0]
some_data = geo_stations[geo_stations["time_stamp"] == some_time]
some_time
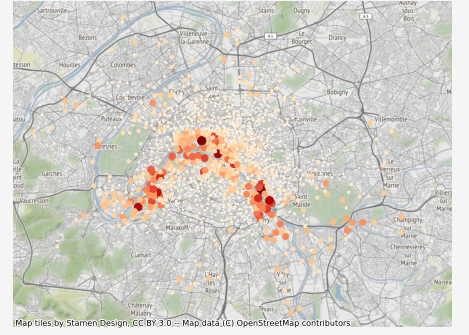
Maintenant nous allons pouvoir ajouter un fond de carte provenant, par exemple, de OpenStreetMap. Il existe un module python pour faire ça en une ligne et cette librairie magique s’appelle contextily. Le seul pré-requis est de convertir les coordonnées GPS au format EPSG:3857, mais GeoPandas fait ça très bien
import contextily as ctx
# Conversion des coordonnées
some_data = some_data.to_crs(epsg=3857)
fig, ax = plt.subplots(figsize=(8, 6))
ax.set_title(some_time.strftime("%A %B %d %H:%M"))
some_data.plot("num_bikes_available", markersize="num_bikes_available", cmap="OrRd", ax=ax)
ax.set_axis_off()
# Ajout du fond de carte
ctx.add_basemap(ax)
plt.show()
Aller plus loin : rassembler les données par quartiers
L’inconvénient majeur de nos cartes est qu’il est difficile de distinguer et de hiérarchiser les zones à forte concentration de vélibs. La raison en est que les marqueurs ont tendance à se chevaucher et que l’on perd en lisibilité. Pour remédier à ce problème, nous allons rassembler les stations appartenant à un même quartier. Ainsi, nous allons tracer des surfaces sur la carte au lieu d’un nuage de points. La liste des quartiers administratifs de Paris est mise à disposition sur le site de la ville de Paris. GeoPandas sait parfaitement importer les fichiers GeoJSON
districts = gpd.read_file("quartier_paris.geojson").to_crs(epsg=3857)
districts
Chaque quartier est donc défini comme un polygone, avec un certain périmètre et une surface. On peut directement tracer les quartiers de Paris sur la carte.
fig, ax = plt.subplots(figsize=(8, 6))
districts.plot(ax=ax, alpha=0.5, edgecolor="white")
ax.set_axis_off()
ctx.add_basemap(ax)
plt.show()
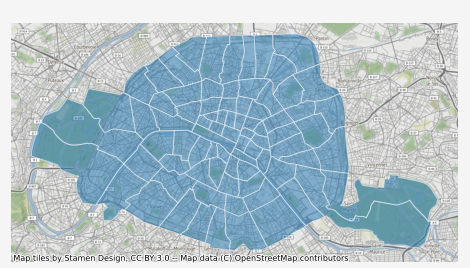
On aimerait disposer du nombre de vélibs présent dans chacun de ces quartiers, et c’est là que se déploie toute la puissance de GeoPandas, voyez plutôt
districts["velib_number"] = districts.apply(
lambda district: (
some_data.within(district.geometry) * some_data["num_bikes_available"]
).sum(),
axis=1
)
Ce bloc mérite quelques explications. On crée une nouvelle colonne nommée velib_number, c’est à dire le nombre de vélibs présents dans le quartier. Pour ce faire, on somme tous les vélos qui sont inclus dans le quartier en question. Cette opération est rendue possible par la méthode .within() qui va déterminer si la station est bien localisée dans le polygone représentant le quartier.
On peut faire la même opération pour calculer le nombre maximum de vélibs dans le quartier, et donc le pourcentage d’occupation des stations dans le quartier
districts["max_velib_number"] = districts.apply(
lambda district: (
some_data.within(district.geometry) * some_data["capacity"]
).sum(),
axis=1,
)
districts["occupation"] = districts["velib_number"] / districts["max_velib_number"]
Enfin, on va tracer le taux d’occupation des stations Vélib, quartier par quartier
fig, ax = plt.subplots(figsize=(8, 6))
districts.plot("occupation", cmap="OrRd", ax=ax, alpha=0.5, edgecolor="white")
ax.set_axis_off()
ctx.add_basemap(ax)
plt.show()
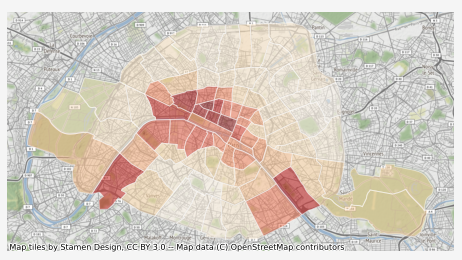
On peut distinguer à l’oeil quelques tendances suivant les quartiers, certains sont actifs la nuit et d’autres le jour. Mais est-il possible de faire mieux qu’une simple analyse à l’oeil ?
Je vous propose une approche complètement automatique pour classifier les différents types de quartier dans Paris, en utilisant l’algorithme des -moyennes.
Séries temporelles par quartier
Le réseau Vélib compte environ 1400 stations et il nous serait difficile de les étudier toutes en même temps. Nous commençons donc par regrouper les données par quartier et par heure.
# Jointure spatiale : on identifie le quartier de chaque observation
geo_districts = gpd.sjoin(districts, geo_stations, how="left")
# On aggrège les données par quartier et par heure
occupation_data = geo_districts.groupby(["l_qu", "time_stamp"], as_index=False).agg({"num_bikes_available":"sum", "geometry": "first"})
occupation_data.head()
La syntaxe est ici plus compacte que dans le précédent épisode donc nous allons la décortiquer ensemble. Dans un premier, nous groupons les données en fonction de l_qu, le nom du quartier et de time_stamp, c’est-à-dire l’heure d’observation. À l’issue de cette opération, on obtient un objet DataFrameGroupBy. Notez l’option as_index=False qui est nécessaire ici.
Puis nous aggrégeons les données avec la méthode .agg(). En argument, on lui dit qu’on veut sommer le nombre de vélos disponibles dans chaque groupe, et garder la géométrie associée au quartier. On peut ne garder que la première occurence, puisque toutes ces géométries sont identiques.
Nous avons donc l’historique, minute par minute, du nombre de vélibs stationnés dans chaque quartier, que nous pouvons visualiser de la façon suivante:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, ax = plt.subplots(figsize=(8,6))
occupation_data.groupby('l_qu').plot(x="time_stamp", y="num_bikes_available", kind="line", ax=ax, legend=False)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M'))
plt.show()
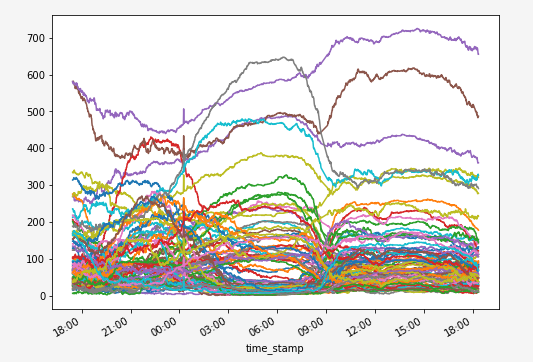
Chacune de ces courbes est une série temporelle qui caractérise l’activité du réseau Vélib dans son quartier. Ce diagramme est un peu brouillon, mais on peut distinguer à l’oeil quelques tendances. Certaines stations semblent se vider en journée quand d’autres semblent se remplir dans le même interval. Mais peut-on faire mieux et de manière automatique ?
Algorithme des k-moyennes
La question que l’on se pose est la suivante : “Est-il possible de classer ces séries temporelles de manières automatique ?”. La réponse est oui, et pour cela nous allons utiliser l’algorithme des -moyennes. Cet algorithme permet de diviser des données en partitions. Sa particularité est de pouvoir être mis en place sans supervisition. C’est à dire qu’il va apprendre tout seul à faire la distinction entre les différentes partitions sans que nous ayons besoin d’intervenir, et c’est précisément ce qu’on lui demande.
Applications aux données temporelles
Commençons l’analyse en mettant nos données sous la forme de séries temporelles pour la librairie tslearn
from tslearn.utils import to_time_series_dataset
from tslearn.preprocessing import TimeSeriesScalerMeanVariance
labels, time_series = [] , []
for l_qu, group in occupation_data.groupby("l_qu"):
labels.append(l_qu)
time_series.append(group["num_bikes_available"].array)
# On formatte les séries temporelles
time_series = to_time_series_dataset(time_series)
# On normalise ces mêmes séries
time_series = TimeSeriesScalerMeanVariance().fit_transform(time_series)
time_series.shape
Rien de particulier ici, si ce n’est que la fonction to_time_series_dataset crée un jeu de données pour tslearn à partir d’un tableau, et que nous normalisons ces données avec l’aide de TimeSeriesScalerMeanVariance qui fait en sorte que chaque série ait pour moyenne et variance . Cette étape est très importante puisqu’elle permet de s’affranchir de nombreux biais comme le nombre absolu de vélibs par quartier, ou la proportion d’habitants utilisant le réseau.
On peut maintenant lancer l’apprentissage non-supervisé de notre modèle avec l’algorithme des -moyennes
from tslearn.clustering import TimeSeriesKMeans
n_classes = 3
model = TimeSeriesKMeans(n_clusters=n_classes, metric="euclidean")
model.fit(time_series)
TimeSeriesKMeans()
Visualisons les barycentres (en rouge) et les différents éléments (gris) de chaque classe que notre modèle a trouvé
import matplotlib.dates as mdates
fig = plt.figure(figsize=(8,n_classes * 3))
# On récupère les dates des différentes observations
time_labels = occupation_data["time_stamp"].unique()
# Pour chaque classe
for yi in range(n_classes):
ax = fig.add_subplot(n_classes, 1, 1 + yi)
# On sélectionne les séries qui correspondent à cette classe
for xx in time_series[model.labels_ == yi]:
ax.plot(time_labels, xx, "k-", alpha=.2)
# Le barycentre de la classe
ax.plot(time_labels, model.cluster_centers_[yi].ravel(), "r-")
# Pour formatter l'heure des observations
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M'))
plt.show()
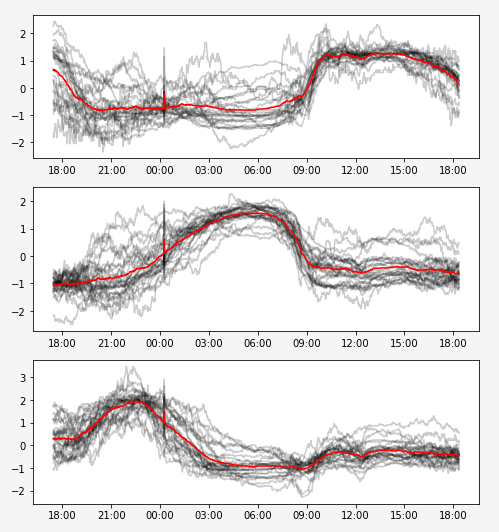
Interprétation et visualisation
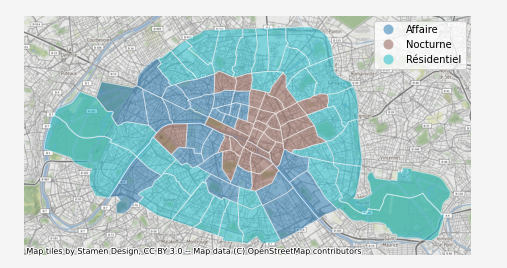
Notre algortihme a classé automatiquement tous les quartiers en trois catégories bien distinctes que l’on peut interpréter comme étant :
1. Les quartiers d’affaires qui se remplissent à 9h du matin et se vident aux alentours de 18h
2. Les quatiers résidentiels qui se remplissent durant la nuit et se vident à 9h
3. Les quartiers d’activités nocturnes qui sont actifs de 18h à minuit environ
Maintenant que nous avons déterminé la classe de chaque quartier, nous pouvons l’ajouter à notre liste des quartiers de Paris
interpretation = ["Affaire", "Résidentiel", "Nocturne"]
classification = pd.DataFrame({"l_qu":labels, "type": [interpretation[classe] for classe in model.labels_] })
districts_classified = districts.merge(classification, on="l_qu")
districts_classified.head()
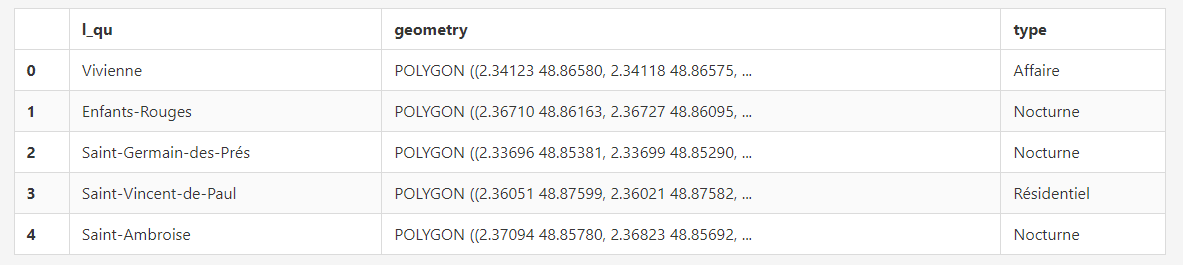 Et produire la carte des types de quartiers dans Paris à partir des données Vélibs
Et produire la carte des types de quartiers dans Paris à partir des données Vélibs
import contextily as ctx
fig, ax = plt.subplots(figsize=(8, 6))
districts_classified = districts_classified.to_crs(epsg=3857)
districts_classified.plot("type", ax=ax, alpha=0.5, edgecolor="white", legend=True)
ax.set_axis_off()
ctx.add_basemap(ax)
plt.show()